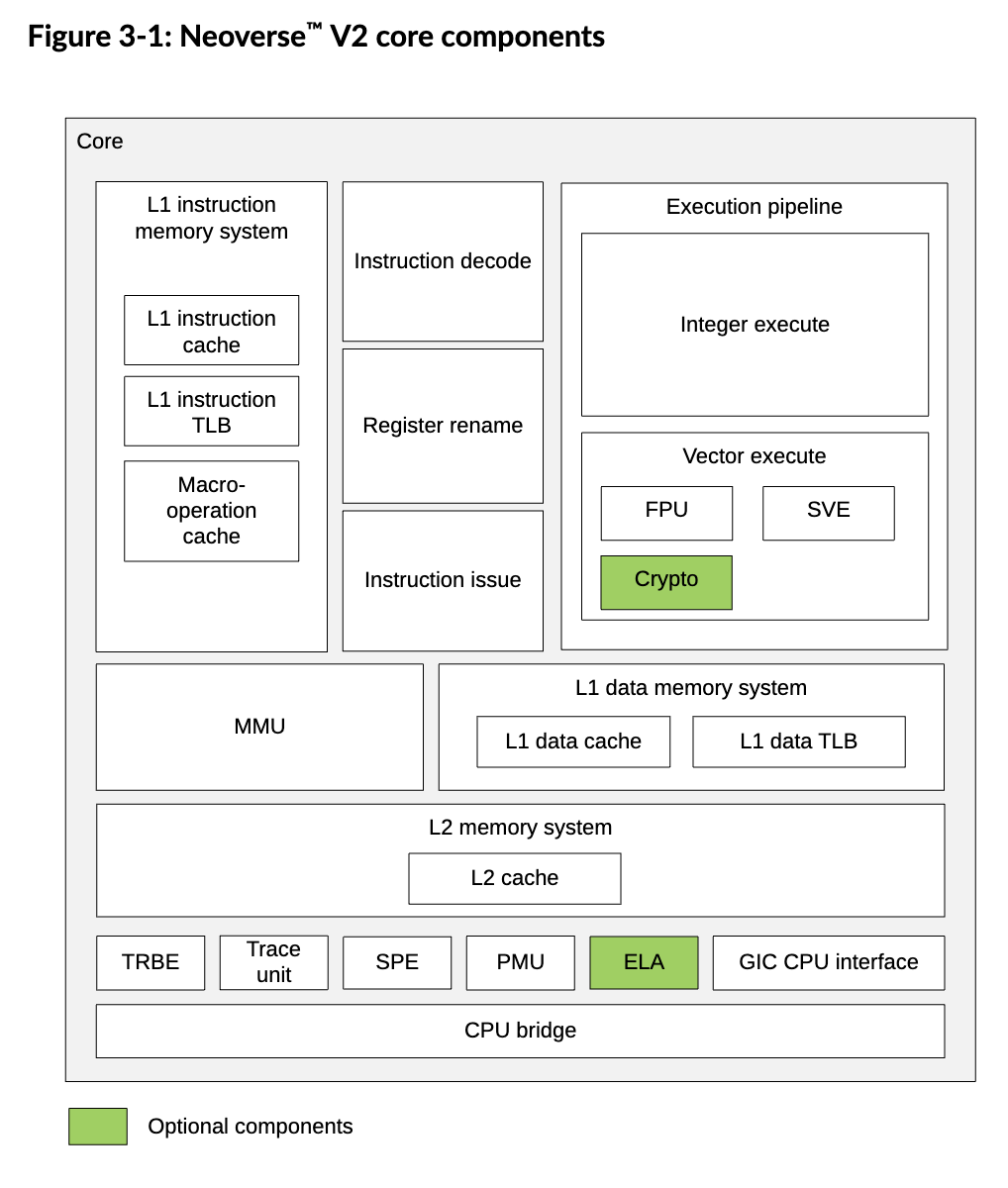
L1 Instruction Memory System
Fetches instruction from the Instruction cache (I$) and delivers the instruction stream to the instruction decode unit.
It includes:
- a 64 KiB (Kibibyte), 4 way Set Associative L1 I$ with 64B lines
- a fully-associative L1 ITLB with native support for 4 KiB, 16 KiB, 64 KiB, and 2 MiB page sizes
- A 1536-entry 4-way skewed associative L0 Macro-Op (MOP) cache, which contains decoded and optimized instructions for higher performance.
- A dynamic branch predictor: TAGe, branch target buffers, return address stacks, etc.
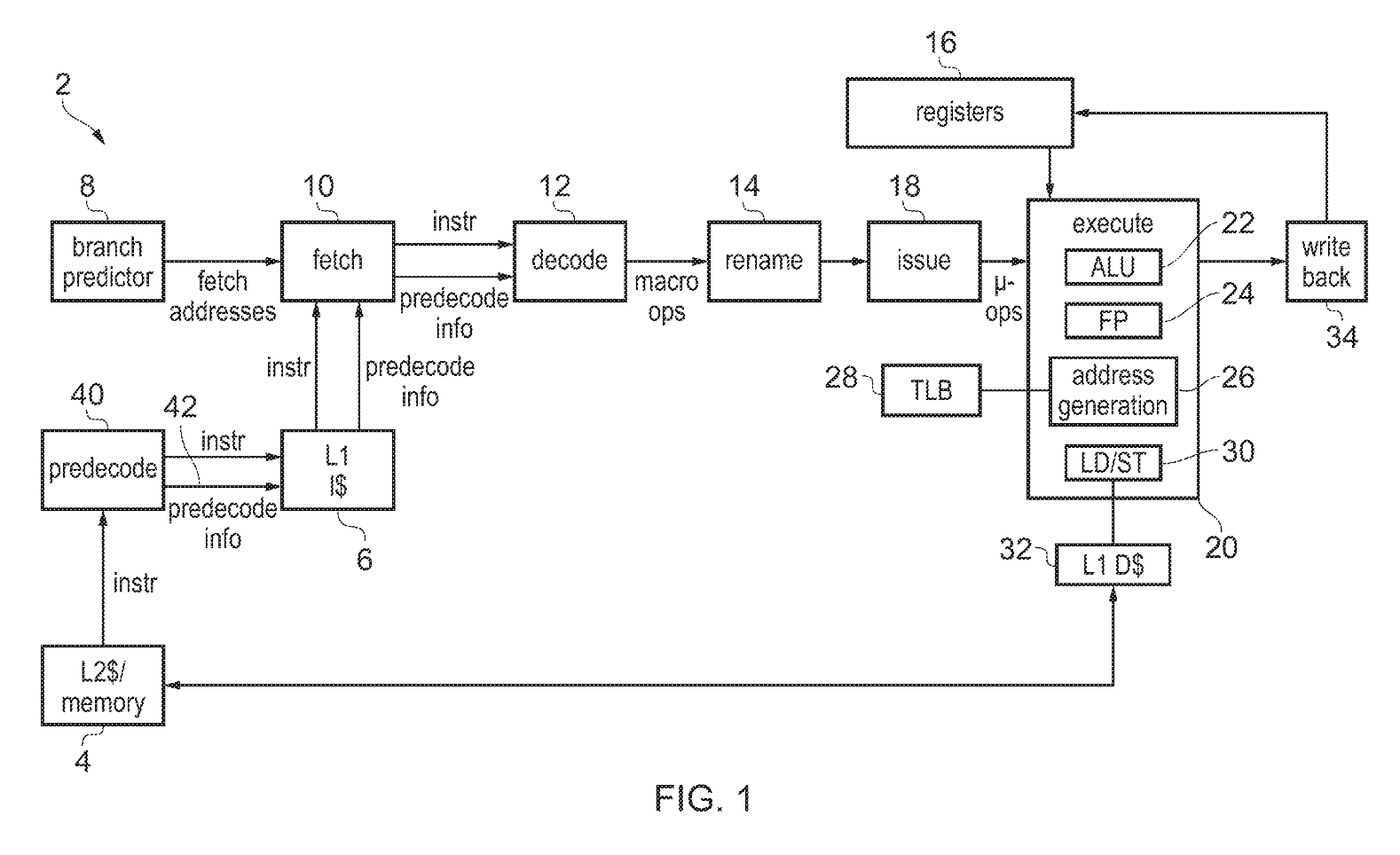
Macro-Ops (MOPs) and Micro-Ops (µops)
Macro-Op (MOP): An instruction held in a format described by the ISA. Can be slight differences, but basically the same. This is independent of the µ-architecture.
Micro-Op (µop): An internal processor specific encoding of the operations used to control execution resources. This can vary widely between different implementations of the same ISA.
The correspondence between MOPs and µops used by a processor may be 1:1, 1:N, or N:1: A single MOP can be cracked/split into one or more internal µops, or multiple MOPs can be fused into a single µop.
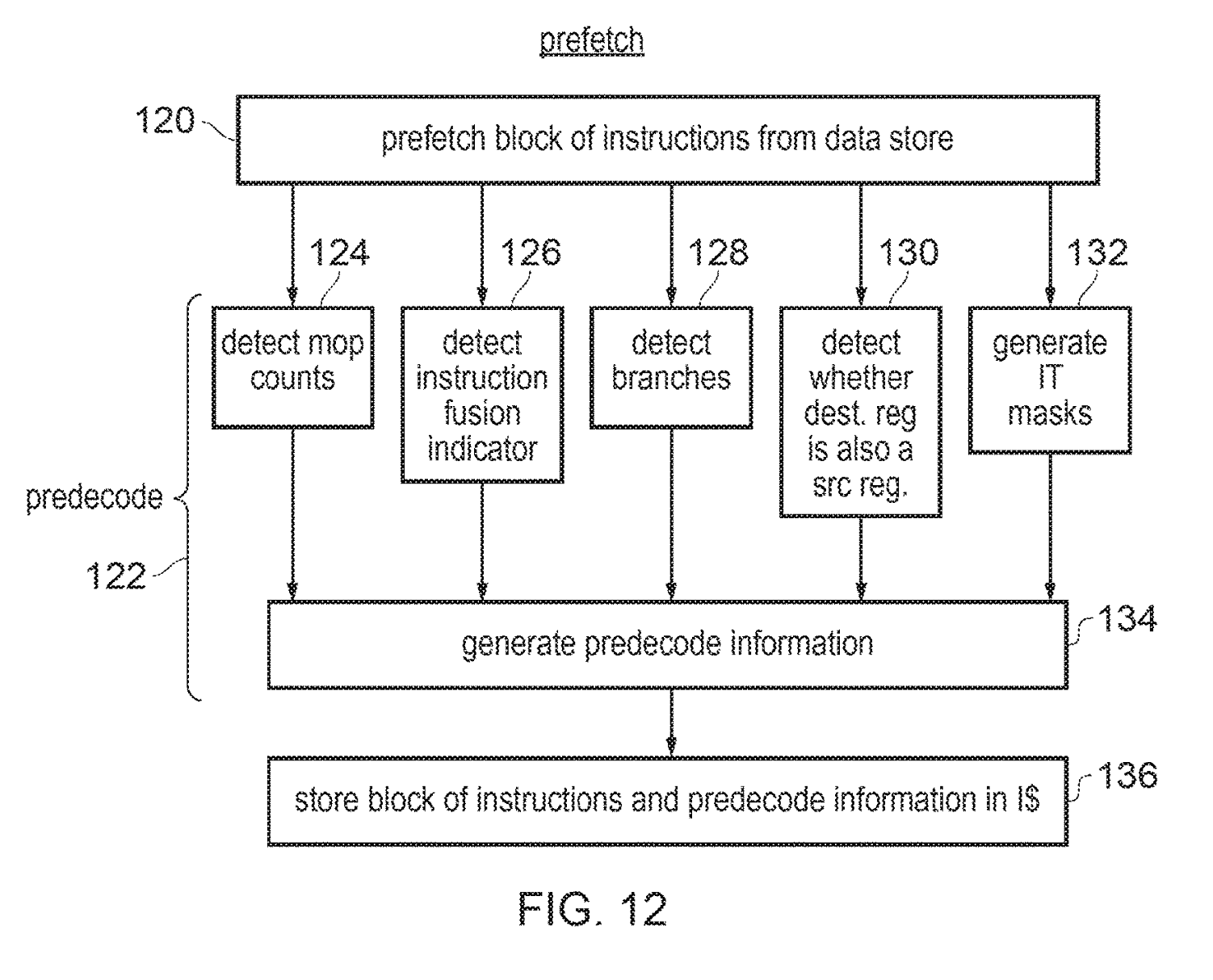
Pre-Decoding
 |
|---|
 |
| https://patents.google.com/patent/US10176104B2/en |
| The intuition is to identify and signal opportunities to split or fuse instructions into more efficient primitives natively supported by the µarch. |
There is, however, a caveat: we need to preserve the precise exception model while doing this.
Examples
Splits
We can split the instruction
str x1, [x2], #24into the MOP sequence
AGU x2
ALU x2, #24
STR x1We can split the instruction
stp x29, x30, [sp, #-32]!into
ALU sp, #-32
AGU sp
STR x29
AGU sp, #8
STR x30Fuses
We can fuse the instruction sequence
add x0, x1, x2
add x3, x0, x4into the single MOP
add r3, r1, r2, r4(assuming the µarch supports 3 register adds)
We can fuse the instruction sequence
b tgt
add x3, x3, 4
tgt: ...into
nop_pc+8We can fuse the instruction
cbnz x1, tgt
add x3, x3, 1
tgt: ...into
ifeqz_add x3, x3, 1, x1, xzrInstruction Decoding in ARM Cortex-A78
A MOP can be split into two µops after the decode stage. These µops are dispatched to one of 13 issue pipelines where each pipeline can accept 1 µop/cycle.
Dispatch can process up to 6 MOPs/cycle and dispatch up to 12 µops/cycle. There are limitations on each type of µop that may be simultaneously dispatched. If there are more µops available to be dispatched, they will be dispatched in oldest to youngest age-order.