GPUs
Graphics processing units use their own microarchitecture to orchestrate and perform operations over data. There are very specific ways to use these processors, since they are highly parallel.
The most common library for GPUs is NVIDIA’s CUDA.
The Graphics Processing Cluster
Structure of a Streaming Multiprocessor (SM)
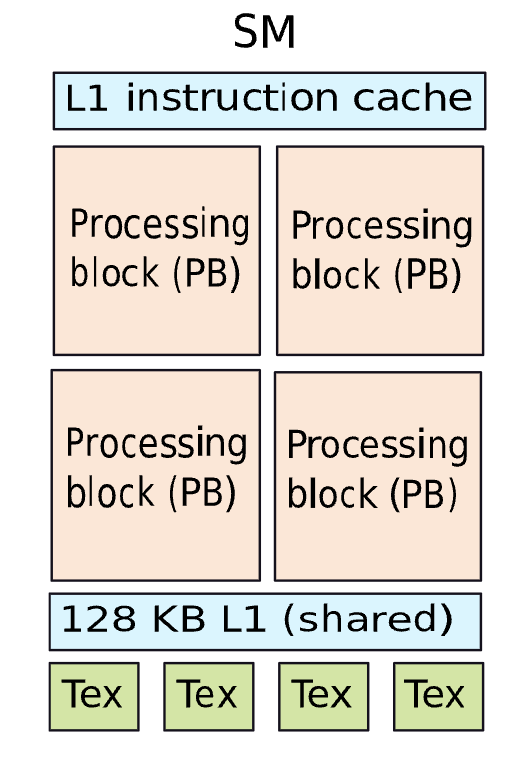
| Type of Memory | Functionality |
|---|---|
| Instruction cache | Similar to an i-cache |
| L1 cache | Stores regular data |
| Texture cache | Stores texture information |
| Constant cache | Stores constants |
| Shared memory | A shared memory that all the threads in the SM can access. Typically, the shared identifier is used to store arrays in this region. |
Warps
On a given unit, we can process a TON of threads at once:
We can’t afford to put a Program Counter (PC) on every thread, that would take up too much memory bandwidth and require a rework of memory systems. Instead, we can create a warp:
- Groups of 32 threads
- Give them all the same PC
- Make them execute in lockstep — this is important, if one thread stalls, the others do, too.
This is analogous to a vector instruction with hardware lanes and clock cycles.
Code with Conditional Branches
Deadlock
Deadlock is possible because of the concept of lockstep. Assume we have 2 threads. If we have one wait on a variable to be updated to 1, the else part of the conditional won’t be executed because of lockstep. All the threads will be stuck waiting at the same PC.
Pipeline Structure
Register File
The register file is massive. We access 32 registers in a single go (warps are 32 threads). As a result, we need to read bits (128B). This means that we need a very very high register reading bandwidth.
The simple solution is to make each entry in a register file bank 1024 bits wide, but this is impractical.
Instead, the better solution would be to distribute the bytes across the banks in the register file. Then, we can use a dedicated set of operand collectors to collect the values of all the registers from different banks. We can have a small on-chip network to route register values between the banks and the operand collector.