NVIDIA CUDA
CUDA: Computer Unified Device Architecture
It is an extension of C++ and allows the user to write code for GPUs. Allows full C++ for the CPU (host) and a subset for the GPU (device). The GPU component is compiled into PTX, which defines a virtual machine and ISA for general-purpose parallel thread execution. It uses an infinite number of registers. PTX programs are translated at install time to the target hardware instruction set by the device driver (JIT compilation).
The CUDA command nvcc is a compiler driver that orchestrates the workflow. It produces a fat binary that contains both GPU and CPU code.
Programming Model
Kernel
A kernel is a C++ function that, when called, is executed times in parallel by different CUDA threads, as opposed to only once like regular C++ functions.
A kernel can be defined using the __global__ declaration specifier.
The number of CUDA threads executing the context is specified using a new <<<...>>> execution configuration.
// Kernel Def
__global__
void VecAdd(float *A, float *B, float *C) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main() {
...
// Kernel Invocation with N Threads
VecAdd<<<1, N>>> (A, B, C);
...
}Each thread that executes VecAdd() performs one addition.
Thread Hierarchy
For convenience, threadIdx is a 3-component vector so that threads can be identified using a one-dimensional, two-dimensional, or three-dimensional thread index, forming a one-dimensional, two-dimensional, or three-dimensional block of threads called a thread block.
- All threads of a block are expected to reside on the same streaming multiprocessor (SM) core and must share the limited memory resources of that core. All threads of a block are guaranteed to be co-scheduled on a SM core. The current limit is 1024 threads per thread block.
- Thread blocks are independent by construction, threads within a block can cooperate via shared memory synchronization.
The index of a thread and its thread ID relate to each other in a straightforward way:
- For a one-dimensional block, they are the same
- For a two-dimensional block of size , the thread ID of a thread of index is
- For a three-dimensional block of size , the thread ID of a thread of index is
__global__
void MatAdd(float A[N][N], float B[N][N], float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation with one block of N * N * 1
threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}Grids of Thread Blocks
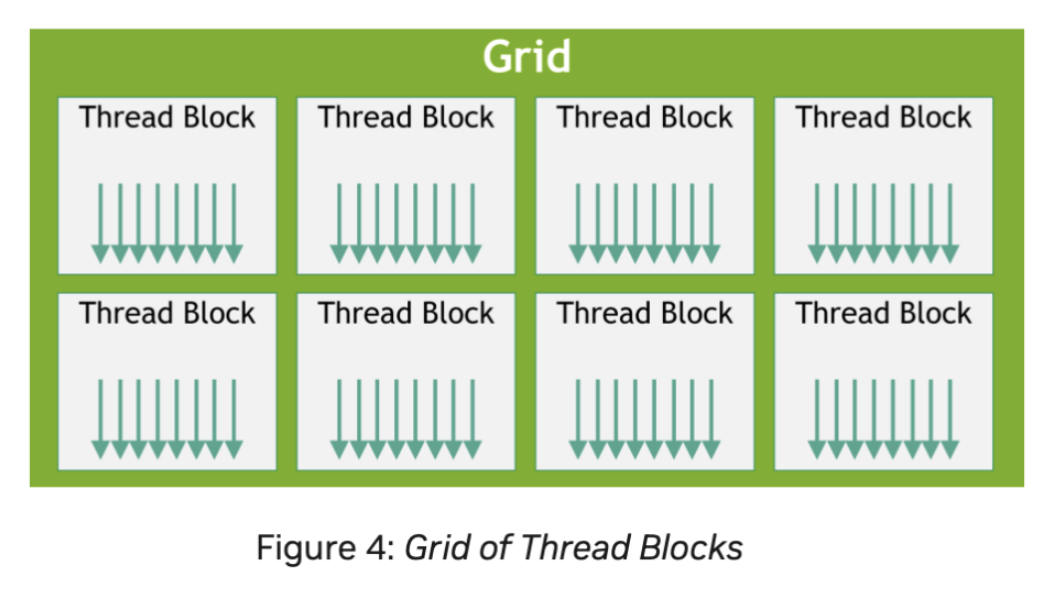
There is once again a hierarchical feature above blocks. Blocks are organized into a one-dimensional, two-dimensional, or three-dimensional grid of thread blocks. The number of thread blocks in a grid is usually dictated by the amount of data being processed, which typically exceeds the number of processors in the system.
Thread Block Clusters
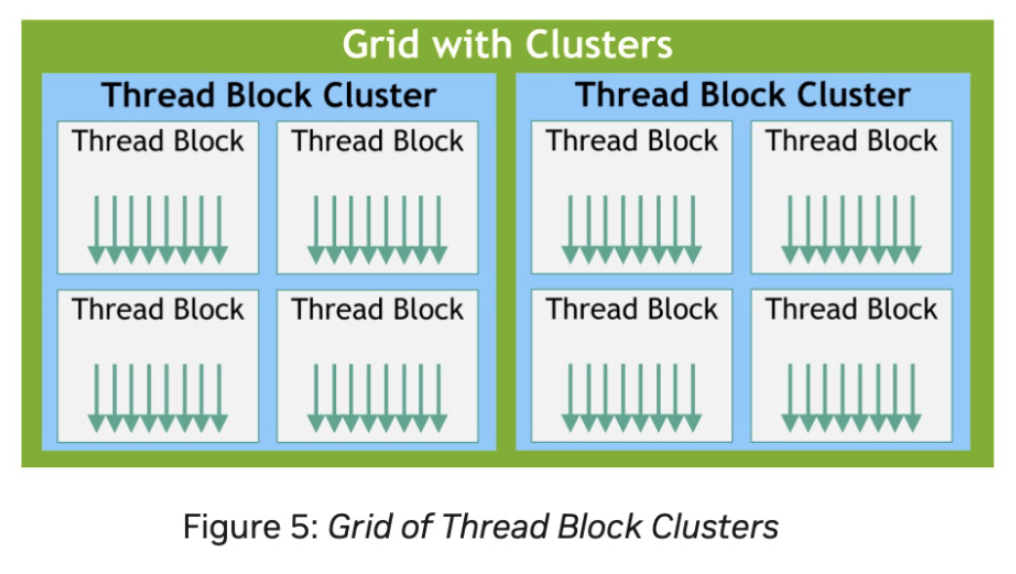
Optional level of hierarchy.
Thread blocks in a cluster are guaranteed to be co-scheduled on a GPU Processing Cluster (GPC) in the GPU. Can be 1-, 2-, or 3-D. There is a max of 8 thread blocks per cluster. Can be enabled either statically or dynamically.
Memory Hierarchy
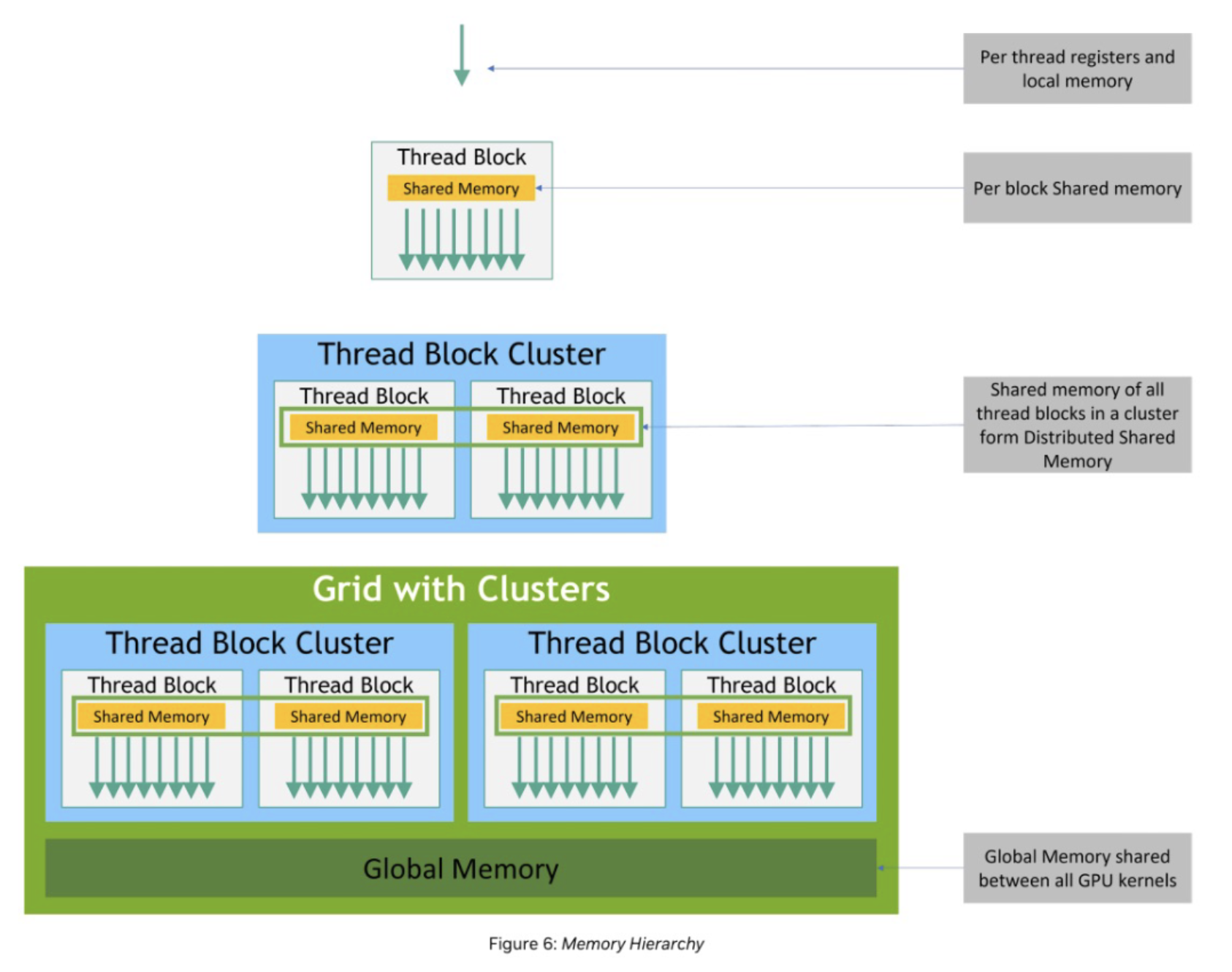
Each thread has private local memory. Each thread block has shared memory visible to all threads of the block and with the same lifetime as the block. Thread blocks in a thread block cluster can perform read, write, and atomic operations on each others’ shared memory (DSM). All threads have access to the same global memory.
Heterogeneous Programming
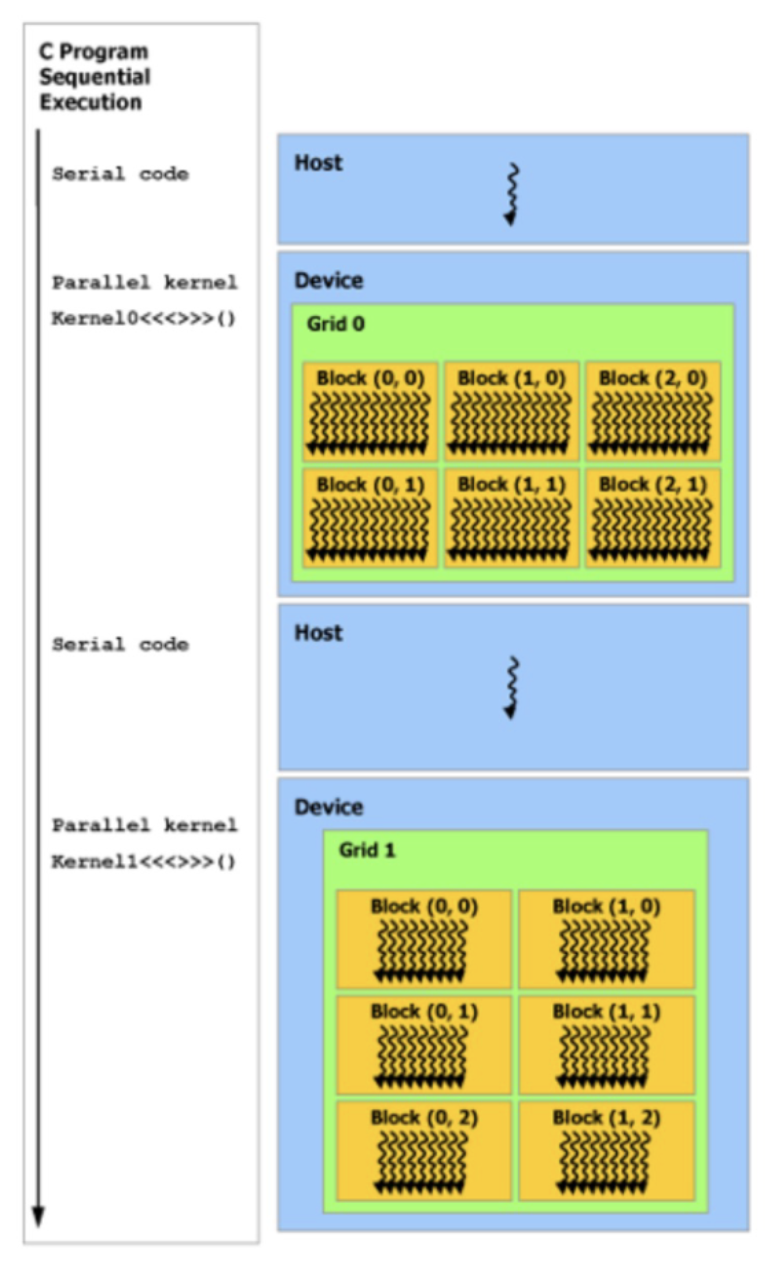
CUDA threads execute on a physically separate device that operates as a coprocessor to the host running the C++ program.
Both the host and the device maintain their own separate memory spaces in DRAM, called host memory and device memory.
Unified Memory provides managed memory to bridge the host and device memory spaces. It is accessible from all CPU and GPUs in the system as a single, coherent memory image with a common address space.