Memory Wall Problem
Optimization focus so far has been reducing the amount of computation. However, on modern machine, most programs that access a lot of data are memory bound. The latency of DRAM is usually on the order of 100-1000 cycles.
Caches can reduce the effective latency of memory access, but programs may need to be rewritten to take full advantage of caches.
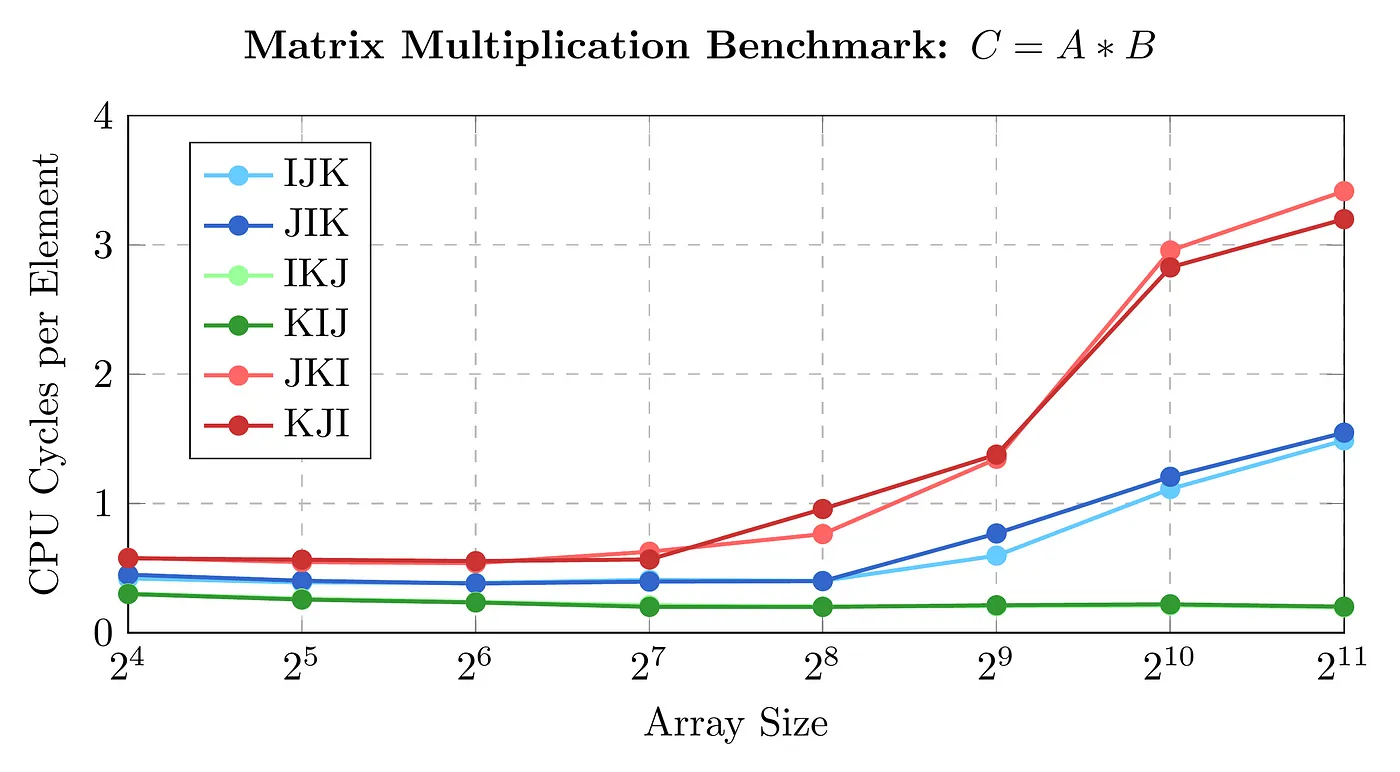
Do Cache Optimizations Matter?
This is best shown by way of Matrix Multiplication. Because matrix multiplication requires multiple passes over the same memory addresses, there is a lot of space for cache optimization.
Two Key Transformations
Loop Interchange/Permutation
for I ...
for J ...
S(I,J);could possibly become:
for J'
for I'
S'(I',J')Loop Tiling/Blocking
Intuition: interleave I and J executions:
for I...
for J...
S(I,J)could possibly become:
for BI...
for BJ...
for I'
for J'
S'(BI,BJ,I',J')Questions
Are these transformations legal?
Is it profitable to perform these transformations?
Is it profitable to perform these transformations?
If so, how can we perform them?
Matrix-Vector Product
Imagine the following code:
for i = 1,N
for j = 1,N
y(i) = y(i) + A(i,j) * x(j)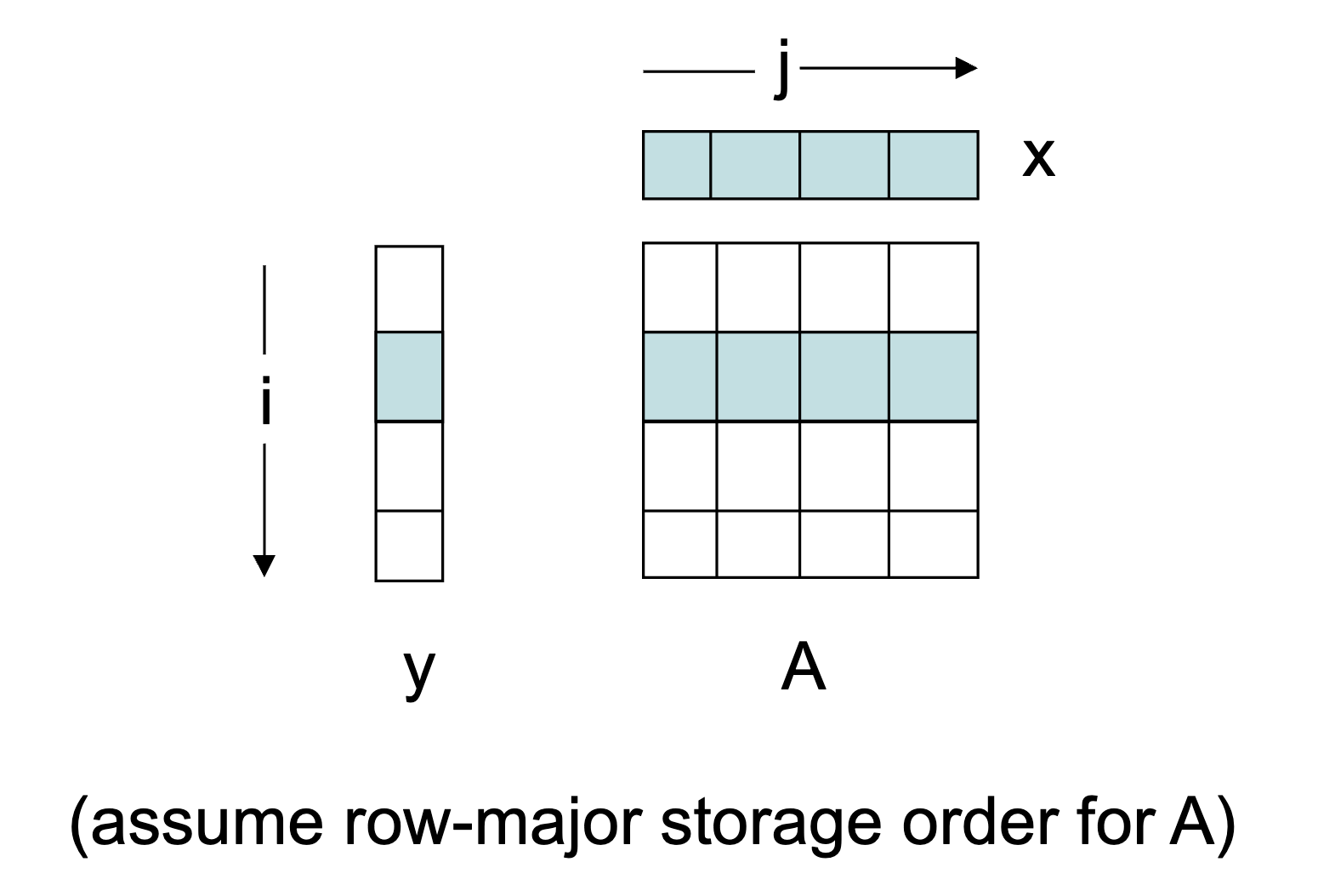
Cache Abstractions
Real caches are very complex, science is all about tractable and useful abstractions (models) of complex phenomena—models are usually approximations. We’ll assume a two level memory model: single-level-cache + memory.
Stack Distance
Lets say and are two memory references where occurs earlier than . : number of distinct cache lines referenced between and .
Modeling Approach
Our first approximation is to ignore conflict misses and only consider cold and capacity misses.
Most problems have the notion of problem size. How does the cache miss ratio change as we increase problem size?
We can often estimate miss ratios at two extremes:
- Large Cache Model: problem size is small compared to cache capacity
- Small Cache Model: problem size is large compared to cache capacity
Large Cache Model
No capacity misses, only cold misses.
Small Cache Model
Cold misses and capacity misses.
Scenario 1
Lets say we have an IJ loop for performing Matrix-vector products.
The cache line size is 1 number.
In the large cache model, we have misses to A, misses to y, and misses to x. The total is , so the miss ratio is which is about .
In the small cache model, we have misses to A, misses to y, and misses to x. The total is , so the miss ratio is which is about .
As the problem size increases, when do capacity misses start to occur? This depends on the replacement policy, the most common is LRU or Pseudo LRU (PLRU).
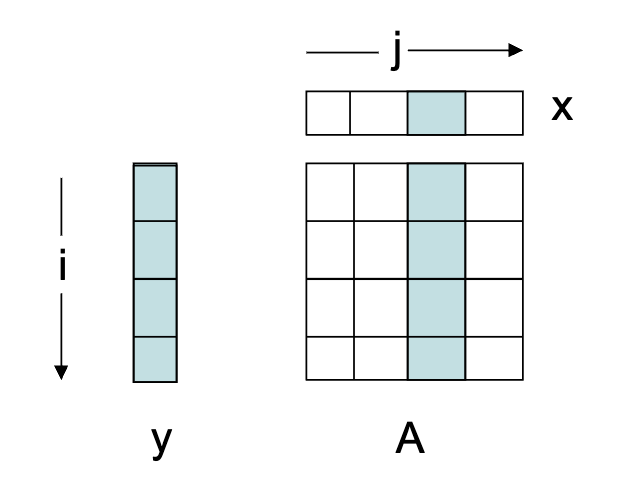
Scenario 2
Lets say we have a JI loop for performing Matrix-vector products.
The miss ratio is the exact same as it was in scenario 1 because the roles of x and y are just interchanged, but the cache line size is simply for a single memory location as defined in scenario 1.
Scenario 3
Say we have the same thing but the cache line size is numbers.
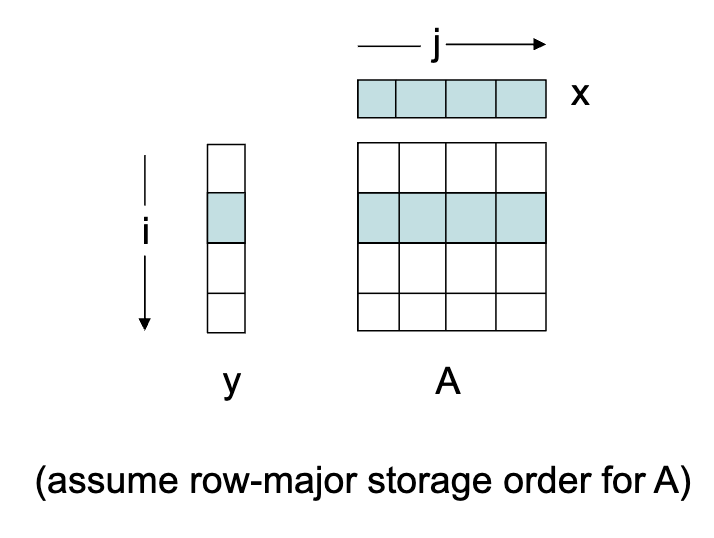
In the large cache model, we have:
- A: misses
- x: misses
- y: misses
- Total: misses
- Miss ratio: